The value of a good database model
You might think that the way your store your data isn't really that important. Well it's more important than you think it is.
A good database design just like good clean code is the key to performance, not only for the end user but also for you the developer. A poor database model just like poorly written code will slow you down and furthermore it will slow your database queries down which results in a slow application.
Just like with the SOLID principles there are some things to consider when developing a database model.
I will try to explain this with a hands-on example.
We have been tasked to create a small application that a user can store information about their music (record) collection. So we need to store the following information.
- Artist/Group
- Title
- Release year
- Format
- Genre
- Number of tracks
- Condition
- Track number
- Track titles
- Track mixes
- Track lengths
- Track artists
There are many ways to accomplish this and some of them are better than others and some of them are plain terrible.
Let's start with an approach that I have seen way too many times, the single Json column approach.
Single json column approach
You create your table with a Json column. In MariaDB the json column has the type longtext
1CREATE TABLE records(2 id int auto_increment primary key,3 record json,4 created_at timestamp,5 updated_at timestamp6);If you use Laravel you would have a migration that looks something like this.
1Schema::create('records', function (Blueprint $table) {2 $table->id();3 $table->json('records');4 $table->timestamps();5}Then you create your json object
1{ 2 "artist": "Iron Maiden", 3 "title": "Killers", 4 "released": 1981, 5 "format": "LP", 6 "genre": "Heavy Metal", 7 "no_of_tracks": 10, 8 "condition": "Mint", 9 "tracks": [10 {11 "track_number": 1,12 "track_title": "The Ides Of March",13 "track_mix": "Album",14 "track_length": "1:48",15 "track_artist": "Iron Maiden"16 },17 {18 "track_number": 2,19 "track_title": "Wrathchild",20 "track_mix": "Album",21 "track_length": "2:54",22 "track_artist": "Iron Maiden"23 },24 {25 "track_number": 3,26 "track_title": "Murders In The Rue Morue",27 "track_mix": "Album",28 "track_length": "4:14",29 "track_artist": "Iron Maiden"30 }31 //...the rest of the tracks here32 ]33 34}The good thing about this approach is that you can store everything in a single table but that is about it. The bad thing about this approach is that it gets trickier to search for the title of the record and even more tricky to search for a specific track title on the record. Not only will your queries be more complex, they will also be slower since you can't really index a json column. There are some ways to do it, but it would be way easier to use a regular table(s) for storing the information.
So why shouldn't you use a single json column
- It's hard to do CRUD on a record or track
- Can't really use indexes
- It's not dry (don't repeat yourself)
- You get more data than you need
Conclusion:
Don't use this approach since it defeats the purpose of a relational database and there are better ways to do this as I soon will show you.
The hybrid table with a json column
In this one you mix the use of regular columns with one json column. Like I said earlier, in MariaDB the Json column type is called longtext.
A brief note on naming conventions.
What a table is named might not seem that important, but it is. Specially when using a framework like Laravel. There aren't that many rules and they are quite easy to follow.
A table is named by its contents plural form. So if the table stores information about a car the name of the table becomes cars. You get the gist, and I will be using that naming convention throughout this post.
The only time this will differ is when creating a pivot table then it should be named from the two joined tables in singular form and in alphabetical order. So if you join a record to an artist with a pivot the name would become artist_record.
If for some reason your table contains house colors then you should use snake case in the name. So the table name would be house_colors.
The column names should be in singular form and if they contain multiple words the should just like the table use snake case. Registration number would become registration_number.
All foreign keys should have the table they are referencing in singular followed by an id. So if a post has a user connected to it the column name would become user_id.
There are a some architects and developers that likes to prefix their column names with the table name. In a records' table the title would be prefixed with records thus becoming records_title. Please don't use that naming convention and if you are going to use that convention there better be a damn good reason for it.
Don't use camel case in your table or column names.
1CREATE TABLE records( 2 id int auto_increment primary key, 3 artist varchar(255), 4 title varchar(255), 5 released int, 6 format varchar(255), 7 genre varchar(255), 8 no_of_tracks int, 9 condition varchar(255),10 tracks json,11 created_at timestamp,12 updated_at timestamp13);In a laravel migration it would look something like this.
1Schema::create('records', function (Blueprint $table) { 2 $table->id(); 3 $table->string('artist'); 4 $table->string('title'); 5 $table->int('released'); 6 $table->string('format'); 7 $table->string('genre'); 8 $table->int('no_of_tracks'); 9 $table->string('condition');10 $table->json('tracks');11 $table->timestamps();12}If you then would do a select you would get a result similar to this.
1---------------------------------------------------------------------------------------------------------------------+ 2|id|artist |title |released|format|genre |no_of_tracks|condition|tracks | 3+-+-----------+-------+--------+------+-----------+------------+---------+-------------------------------------------+ 4|1|Iron Maiden|Killers|1981 |LP |Heavy Metal|10 |Mint |[{"track_number": 1, | 5 | "track_title": "The Ides Of March", | 6 | "track_mix": "Album", | 7 | "track_length": "1:48", | 8 | "track_artist": "Iron Maiden"}, | 9 | {"track_number": 2, |10 | "track_title": "Wrathchild", |11 | "track_mix": "Album", |12 | "track_length": "2:54", |13 | "track_artist": "Iron Maiden"}, |14 | {"track_number": 3, |15 | "track_title": "Murders In The Rue Morue",|16 | "track_mix": "Album", |17 | "track_length": "4:14", |18 | "track_artist": "Iron Maiden"}] |19+-+------+----+-+-----+---+----+------+------+----+------------+---------+-------------------------------------------+201 row in set (0.000 sec)Using this approach still put everything in the same table and while it's better than the first approach because you can easily index and do CRUD operations on the record you still have the same issue with the tracks.
So why shouldn't you use the hybrid approach
- It's hard to do CRUD on a track
- Can't really use indexes on the tracks
- It's DRYer but not DRY
- You get more data than you need
Conclusion:
Don't use this approach.
The two table approach
With this approach we extract the tracks to its own table and use a foreign key to create a relation between the two tables.
The records table
1CREATE TABLE records( 2 id int auto_increment primary key, 3 artist varchar(255), 4 title varchar(255), 5 released int, 6 format varchar(255), 7 genre varchar(255), 8 no_of_tracks int, 9 condition varchar(255),10 created_at timestamp,11 updated_at timestamp12);Laravel Migration
1Schema::create('records', function (Blueprint $table) { 2 $table->id(); 3 $table->string('artist'); 4 $table->string('title'); 5 $table->int('released'); 6 $table->string('format'); 7 $table->string('genre'); 8 $table->int('no_of_tracks'); 9 $table->string('condition');10 $table->timestamps();11}The tracks table
1CREATE TABLE tracks( 2 id int auto_increment primary key, 3 track_no int, 4 title varchar(255), 5 mix varchar(255), 6 length varchar(255), 7 track_artist varchar(255), 8 record_id int, 9 created_at timestamp,10 updated_at timestamp11);Laravel Migration
1Schema::create('tracks', function (Blueprint $table) { 2 $table->id(); 3 $table->int('track_no'); 4 $table->string('title'); 5 $table->string('mix'); 6 $table->string('length'); 7 $table->string('track_artist'); 8 $table->foreign('record_id'); 9 $table->timestamps();10}Our database model now looks like this
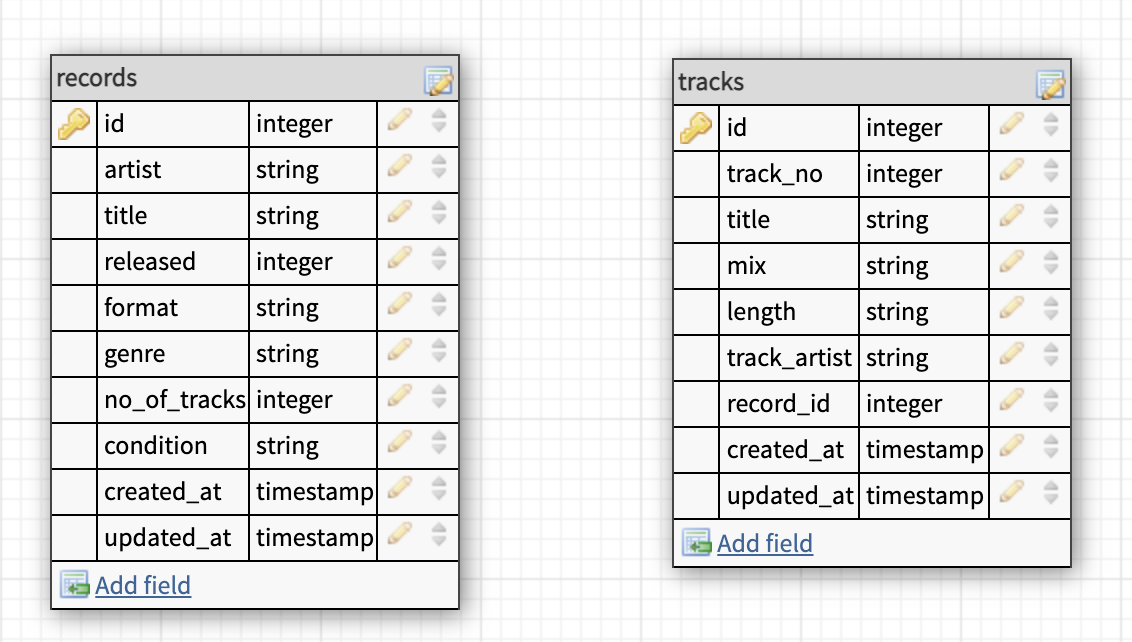
We can then tell our database that there is a relation between the id of our records table and our tracks table. While doing that we also prevent the creation of tracks that does not belong to a record.
1CREATE TABLE tracks( 2 id int auto_increment primary key, 3 track_no int(255), 4 title varchar(255), 5 mix varchar(255), 6 length varchar(255), 7 track_artist varchar(255), 8 record_id int, 9 created_at timestamp,10 updated_at timestamp,11 FOREIGN KEY (record_id) REFERENCES records(id)12);Laravel Migrationfile
1Schema::create('tracks', function (Blueprint $table) { 2 $table->id(); 3 $table->int('track_no'); 4 $table->string('title'); 5 $table->string('mix'); 6 $table->string('length'); 7 $table->string('track_artist'); 8 $table->foreignId('record_id') 9 ->constrained('records');10 $table->timestamps();11}This is what our model looks like with the relation defined.
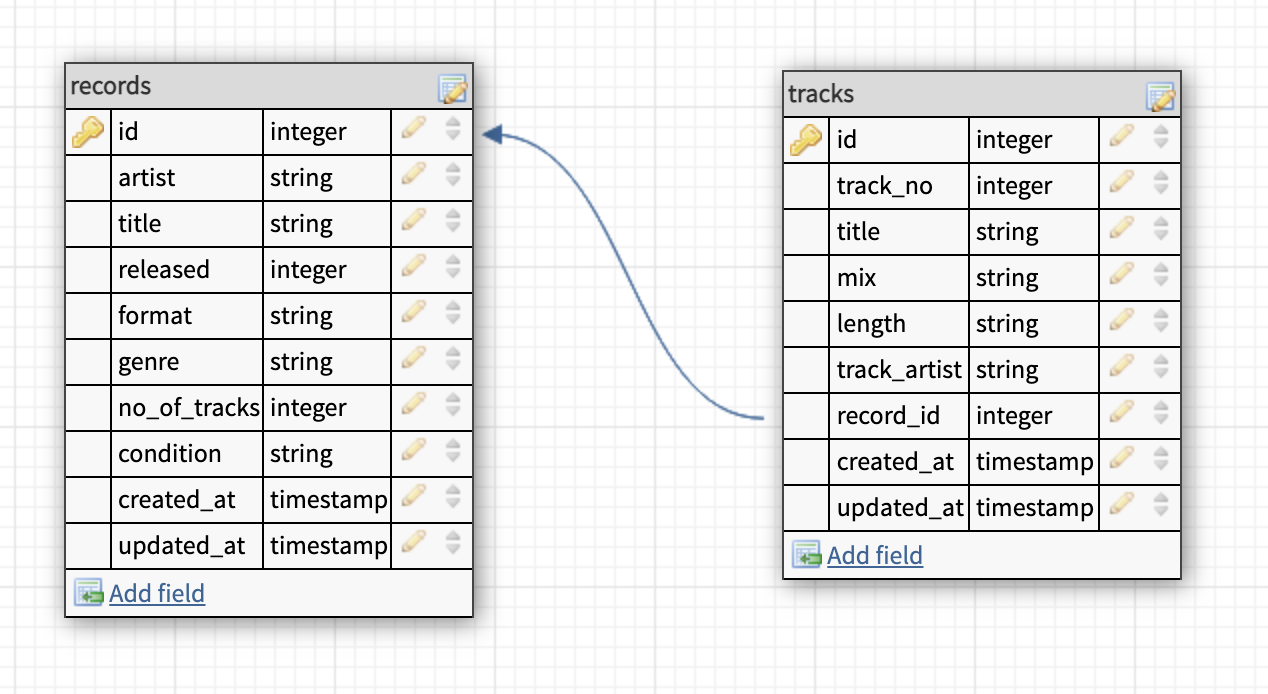
The important thing here is that the data type of both the id and the record_id are exactly the same,
or you will get an error when creating the tracks table.
You must also create the records table first otherwise you will get an error while creating the tracks table.
Another benefit to linking the tables with the id and the record_id is that you can use cascade
to make changes in the related table.
For example if you delete the record you will also delete all the track that belongs to that record.
To make that work we need to tell the database that it should cascade the action.
This is how you can do that
1CREATE TABLE tracks( 2 id int auto_increment primary key, 3 track_no int, 4 title varchar(255), 5 mix varchar(255), 6 length varchar(255), 7 track_artist varchar(255), 8 record_id int, 9 created_at timestamp,10 updated_at timestamp,11 FOREIGN KEY (record_id) REFERENCES records(id)12 ON DELETE CASCADE13);Laravel Migration
1Schema::create('tracks', function (Blueprint $table) { 2 $table->id(); 3 $table->int('track_no'); 4 $table->string('title'); 5 $table->string('mix'); 6 $table->string('length'); 7 $table->string('track_artist'); 8 $table->foreignId('record_id') 9 ->constrained('records')10 ->onDelete('cascade');11 $table->timestamps();12}Now we can easily use CRUD on both our tables, and we can add any necessary indexes to increase the performance. We are also using a one to many relation between the record and the tracks.
A record has many tracks.
So why shouldn't you use the two table approach
- It's DRYer but not DRY
Conclusion:
While this approach is better than the two previous ones it still lacks the DRY:ness that we need. It still defeats the relational database purpose. Let me explain.
We store the full artist name in our records table and most artists has more than one record. We also store the full artists name in our tracks table. Then we do the same with format, genre and condition in our records table. While this might not seem like a big issue, it kinda is. Your database will be a bit bigger since you are storing more information than necessary, and you are violating the single source of truth principle. Imagine you want a list of all the Iron Maiden records and someone has spelled it Iron Maden then you would not find that record. So try not to use this approach since it can give some unexpected results to your queries.
The extraction principle
For every column in a table ask yourself these questions
- Can
xhave more than oney? - Can
yhave more than onex?
So let's apply it to our original columns list.
- Artist/Group
- Title
- Release year
- Format
- Genre
- Number of tracks
- Condition
- Track number
- Track titles
- Track mixes
- Track lengths
- Track artists
Artist
Can an artist have more than one record?
Yes!
Can a record have more than one artist?
Yes!
Now there are two approaches to the artist/record dilemma.
- Use a many-to-many relation with a pivot table
- Use the track artist approach that we have been doing.
I would go with the second approach since I then can give the record a Various Artists artist or if it's a certain
series of records featuring various artists, and you want to keep them together like the Thunderdome series.
There are some edge cases, but they are so few that I don't think it warrants a many-to-many relation.
To create our artists' table we can use this SQL.
1CREATE TABLE artists(2 id int auto_increment primary key,3 artist varchar(255),4 created_at timestamp,5 updated_at timestamp6);If you are a Laravel user your migration would look something like this.
1Schema::create('artists', function (Blueprint $table) {2 $table->id();3 $table->string('artist');4 $table->timestamps();5}So we end up with an artists' table that looks like this.
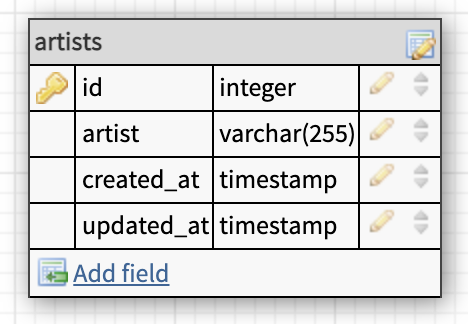
Title
Can a record have more than one title?
Generally no. Some might have like Metallica's The Black Album aka Metallica. However I think we are safe to presume a no here.
Can a title belong to more than one record?
Yes, however not likely with the same artist unless of course you count Edguy's re-recording of their 1995 release Savage Poetry in 2000.
Here I would stick with keeping the title in the records' table since there is no real gain in extracting it to its own table.
Our records' table so far.

Release
Can a record have more than one release year?
Yes it can, but now we are talking about reissues, and it would be better to add
another column to our records' table to handle that.
Can a year have more than one release?
Of course, it can but would it warrant another table? I don't think so and keeping it in the records table and putting an index on it would make listing records form a certain year lightening fast.
So here I would stick with keeping it in the records table.
Like so.
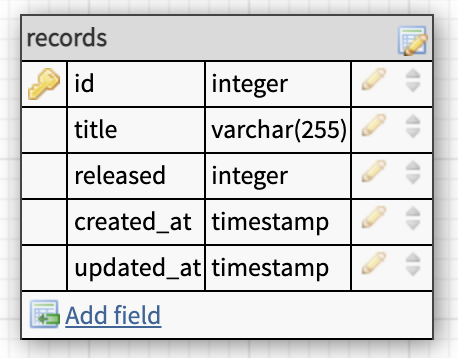
Format
Can a record have more than one format?
Yes!
Can a format have more than one record?
Yes!
Here we have a similar situation as with the Record/Artist relation. We could use a many to many here. However, it depends a bit on how you want to display the records.
Do you want it like this?
- Iron Maiden - Killers LP, CD, TAPE
Or Like this?
- Iron Maiden - Killers LP
- Iron Maiden - Killers CD
- Iron Maiden - Killers TAPE
The first option would require a many-to-many relation with a pivot table to join the formats to the record. The second option would just require a formats table and a foreign key in your records' table referencing the formats table.
I would use a one to many on this by adding the foreign key to my records' table but the other approach is fine as well.
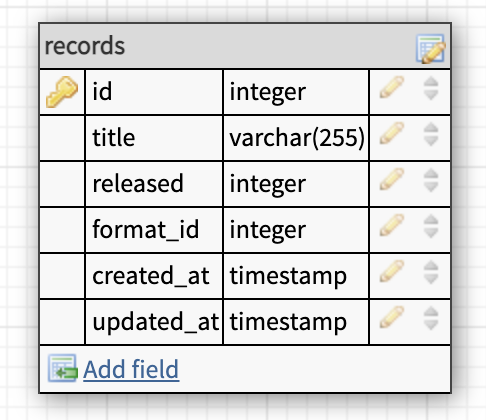
Genre
Can a record have more than one genre?
Yes!
Can a genre have more than one record?
Yes!
This one is almost the same as the format, however we can't look at how we want to display the record to decide which approach to take.
This would make sense
- Iron Maiden - Killers Heavy Metal, Hard Rock
This would not
- Iron Maiden - Killers Heavy Metal
- Iron Maiden - Killers Hard Rock
So the question here is, should we allow only one genre per record or multiple genres.
I would be happy to keep the genres to a minimum and use a foreign key in the records table, but it depends on what your need is.
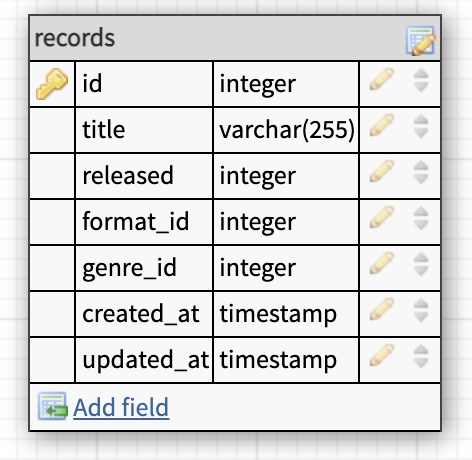
No_of_tracks
Can a record have more than one number of tracks?
Yes, but then it's another version of that record.
Can a track number have many records?
Yes!
This one is similar to the released column. I think using a pivot because a few percent of the records has the same number of tracks is overengineering it a bit. So I see no reason to extract it to a reference table. So I would keep it in the records table.
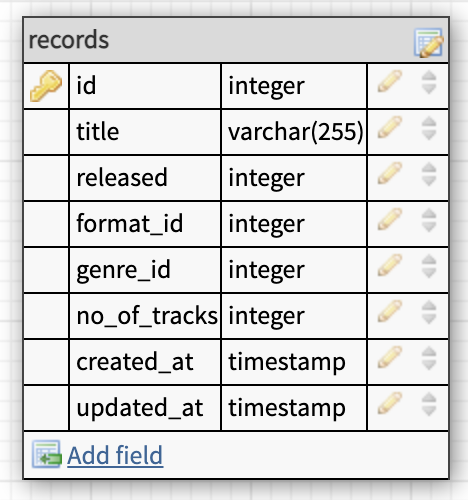
Condition
Can a record have more than one condition
Yes, if you count the covers condition.
Can a condition have more than one record?
Yes!
Here you can choose to do a polymorphic relation with a pivot table with three columns
- record_id
- condition_id
- type
Where type is the cover or the record.
Or you can just add another column for the cover condition.
I would go with the added foreign key in the records table approach for this, but it's up to you which way you choose.
So we end up with a records that looks like this.
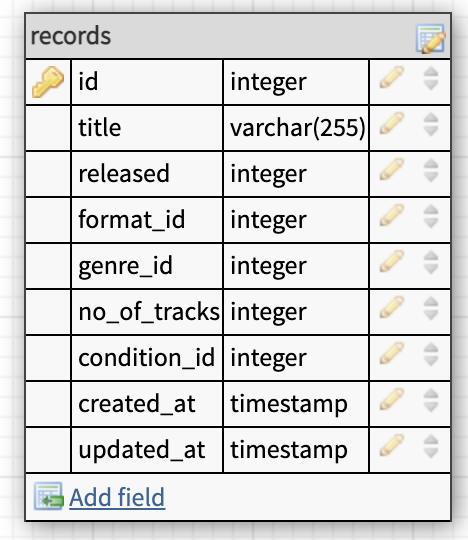
We also need to create the foreign key that connects the artists table with the records table. The most important thing here is that they both have the same datatype or our database will squawk at us.
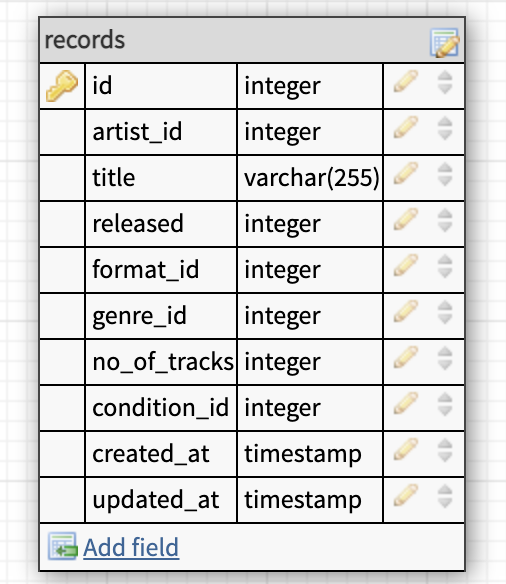
We can also add a constraint to our foreign key and with the help of that we can delete all the records automatically when the artist is deleted. So we create a foreign key constraint with a cascade on delete. This constraint also prevents us from creating records that doesn't have an artist.
To create the records table we can use an SQL script that looks something like this.
1CREATE TABLE records( 2 id int auto_increment primary key, 3 artist_id int, 4 title varchar(255), 5 released int, 6 format_id int, 7 genre_id int, 8 no_of_tracks int, 9 condition_id int,10 FOREIGN KEY (artist_id)11 REFERENCES artists (id)12 ON DELETE CASCADE13);And in Laravel the migration would look something like this.
1Schema::create('records', function (Blueprint $table) { 2 $table->id(); 3 $table->foreign('artist_id') 4 ->refrences('artists') 5 ->on(id) 6 ->onDelete('cascade'); 7 $table->string('title'); 8 $table->int('released'); 9 $table->foreign('format_id');10 $table->foreign('genre_id');11 $table->int('no_of_tracks');12 $table->foreign('condition_id');13}This is what our database model looks like so far. We have the artists table and the records table, we have added a foreign key constraint with a cascade on delete.
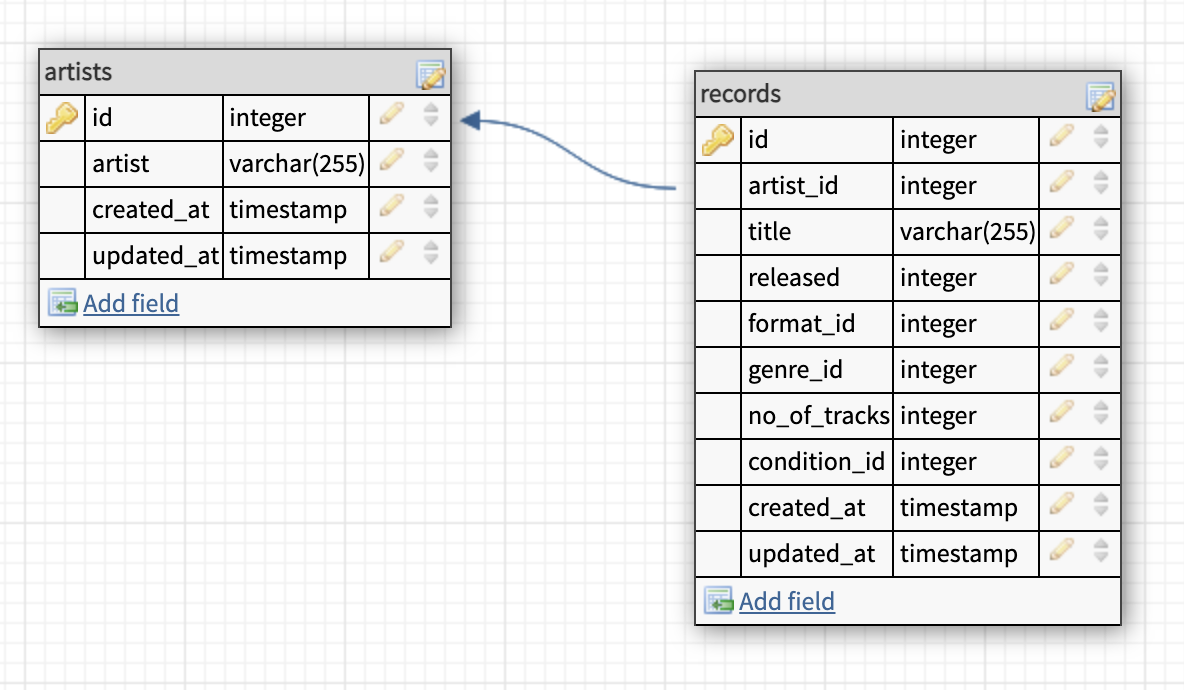
Before we move on with the tracks table we need to create the tables for formats, genres and conditions. These three tables will have the same structure, the only thing that differs is the table names.
This is the SQL for creating the table, just replace the <table name>
with each of the table name you want to create.
1CREATE TABLE <table name> (2 id int auto_increment primary key,3 name varchar(255),4 created_at timestamp,5 updated_at timestamp6);If you are a Laravel user your migration would look something like this.
1Schema::create('<table name>', function (Blueprint $table) {2 $table->id();3 $table->string('name');4 $table->timestamps();5}We should now have a model that looks like this.
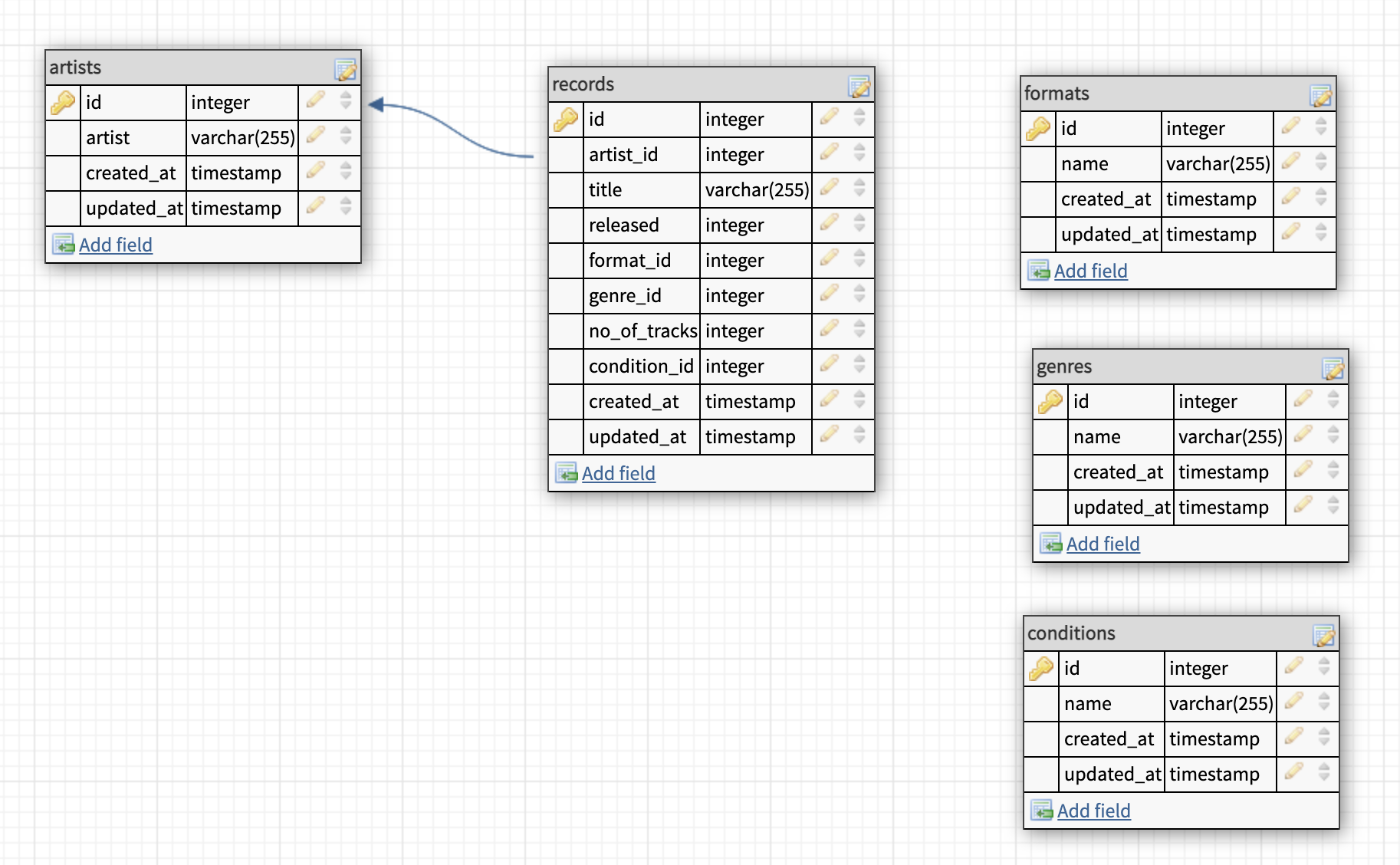
Now we need to connect the foreign keys together as we did with the artists and records tables. The good thing is that we only need to update the records table like this.
In SQL
1CREATE TABLE records( 2 id int auto_increment primary key, 3 artist_id int, 4 title varchar(255), 5 released int, 6 format_id int, 7 genre_id int, 8 no_of_tracks int, 9 condition_id int,10 FOREIGN KEY (artist_id)11 REFERENCES artists (id)12 ON DELETE CASCADE,13 FOREIGN KEY (format_id)14 REFERENCES formats (id),15 FOREIGN KEY (genre_id)16 REFERENCES genres (id),17 FOREIGN KEY (condition_id)18 REFERENCES conditions (id)19);And in Laravel the migration would look something like this.
1Schema::create('records', function (Blueprint $table) { 2 $table->id(); 3 $table->foreign('artist_id') 4 ->refrences('artists') 5 ->on(id) 6 ->onDelete('cascade'); 7 $table->string('title'); 8 $table->int('released'); 9 $table->foreign('format_id')10 ->references('formats')11 ->on('id');12 $table->foreign('genre_id')13 ->references('genres')14 ->on('id');15 $table->int('no_of_tracks');16 $table->foreign('condition_id')17 ->references('conditions')18 ->on('id');19}As you probably noticed I didn't add any cascade on the foreign keys for the formats, genres and conditions tables. This is because they don't really have that strong connections like artist and record. We could add them, but I don't see the need since the data in these will very seldom change, much less be deleted.
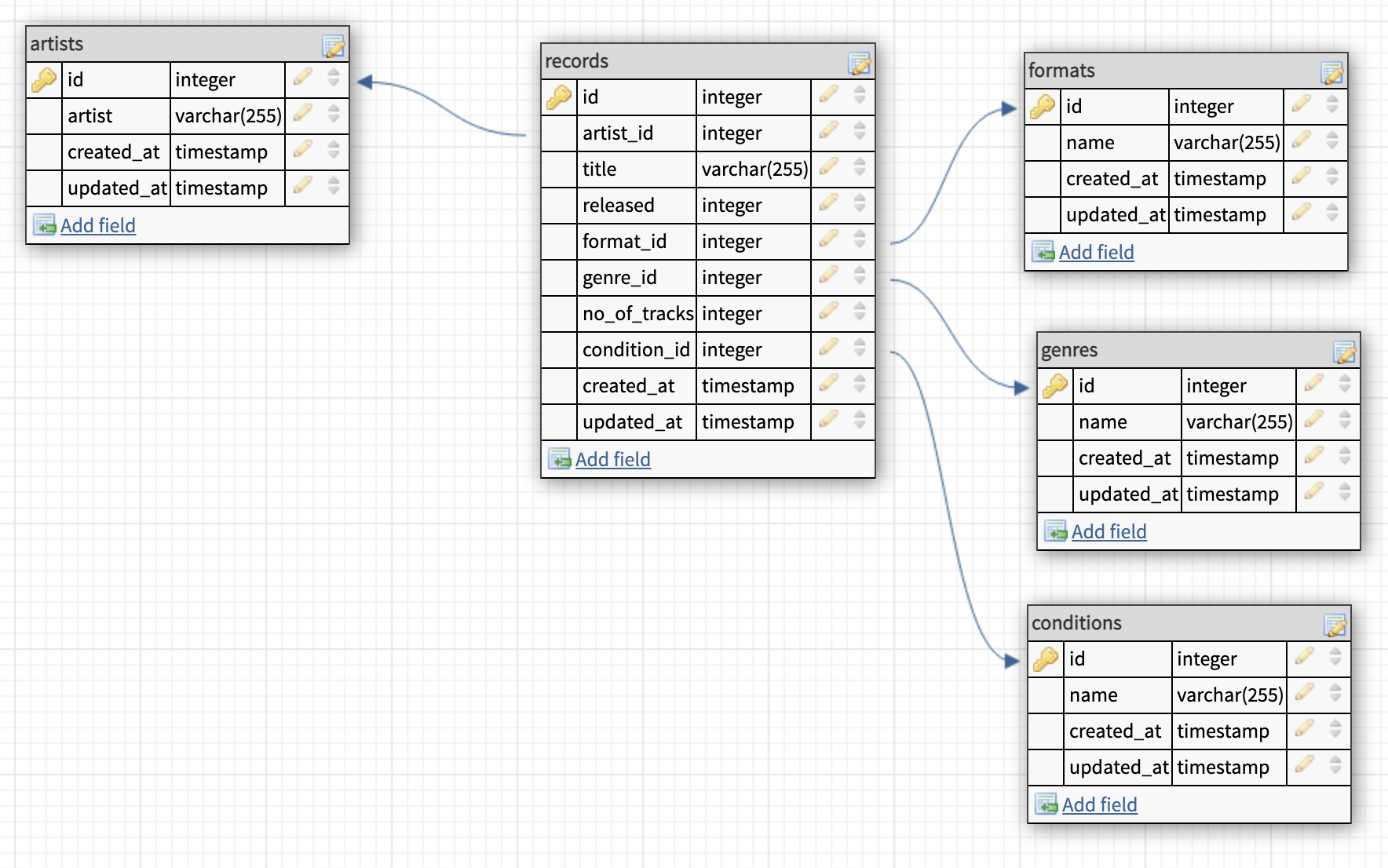
We now do the same for the tracks table.
- Track number
- Track titles
- Track mixes
- Track lengths
- Track artists
Track number
Can a track have more than one number?
Yes!
Can a number have more than one track?
Yes!
Using a many to many here is a bit complicated since you also need to consider the record_id, so it would be a polymorphic many to many here as well just like we did with the many-to-many approach with the condition.
- record_id
- track_id
- track_number
I think that is overthinking it, so I'm happy to keep the track number in the tracks table.
Track title
Can a track have more than one title?
Generally no, unless the track is renamed on the European release like Naughty By > Nature's
Ghetto Bastardthat was namedEverything's Gonna Be Alrightin Europe.
Can a track title have more than one track?
Yes, it could but the mix, length would probably differ.
Does this feel repetitive? Yep. Same as with the record title sticking with having it in the tracks table is the best approach in my opinion.
Track mix
Can a track have more than one mix?
Yes, but not with the same track number
Can a mix have more than one track?
Yes, but not likely
I suggest sticking with keeping the mix column in the tracks table.
Track length
Can a track have different lengths?
Yes, but it would also be a different mix of the track.
Can a length have many tracks?
Yes, but we would be overthinking it again.
Here I strongly suggest keeping the length in the tracks table.
We also need to connect the artists and the records table, and we do that with a foreign key named record_id.
We end up with a create script that looks something like this.
1CREATE TABLE tracks( 2 id int auto_increment primary key, 3 track_no int, 4 title varchar(255), 5 mix varchar(255), 6 length varchar(255), 7 record_id int, 8 created_at timestamp, 9 updated_at timestamp,10 FOREIGN KEY (record_id) REFERENCES records(id)11 ON DELETE CASCADE12);Laravel migration.
1Schema::create('tracks', function (Blueprint $table) { 2 $table->id(); 3 $table->int('track_no'); 4 $table->string('title'); 5 $table->string('mix'); 6 $table->string('length'); 7 $table->foreignId('record_id') 8 ->constrained('records') 9 ->onDelete('cascade');10 $table->timestamps();11}As you might have noticed we haven't talked about the track artist and that is up next.
Track artist
Can a track have more than one artist?
Yes!
Can an artist have more than one track?
Yes!
Here we have a similar dilemma as with artist and record.
There are three approaches to the artist/track dilemma.
- Use a many-to-many relation with a pivot table
- Use the track artist for any additional (Featuring) artists.
- Put the featuring artists in the tracks title.
This decision depends on how precise you need to be.
- Very precise
- Pretty precise
- Not that precise
Approach two and three gives some issues with showing all tracks that is made or featured by given artist. The best approach would be to extract the track artist to a pivot. We didn't use this approach in the records table but, we could have done that and if you like you can make the necessary changes yourself.
- track_id
- artist_id
In a pivot table the created_at and the updated_at are quite optional, but I like to keep them there. So let's create our pivot table.
1CREATE TABLE artist_track(2 id int auto_increment primary key,3 artist_id int,4 track_id int,5 created_at timestamp,6 updated_at timestamp,7 FOREIGN KEY (artist_id) REFERENCES artists(id),8 FOREIGN KEY (track_id) REFERENCES tracks(id)9);The Laravel migration.
1Schema::create('artist_track', function (Blueprint $table) {2 $table->id();3 $table->foreignId('artist_id')4 ->constrained('artists')5 $table->foreignId('track_id')6 ->constrained('tracks');7 $table->timestamps();8}Notice the naming convention on the table name. You can name these almost anyway you like but by following the Laravel standard for pivot tables (the table names in singular form and in alphabetic order).
The artists' table becomes artist and the tracks' table become tracks thus making the name artist_track. The main reason for following this standard is that the framework gives you some stuff for free.
So our tracks and our artist_track tables end up looking like this.
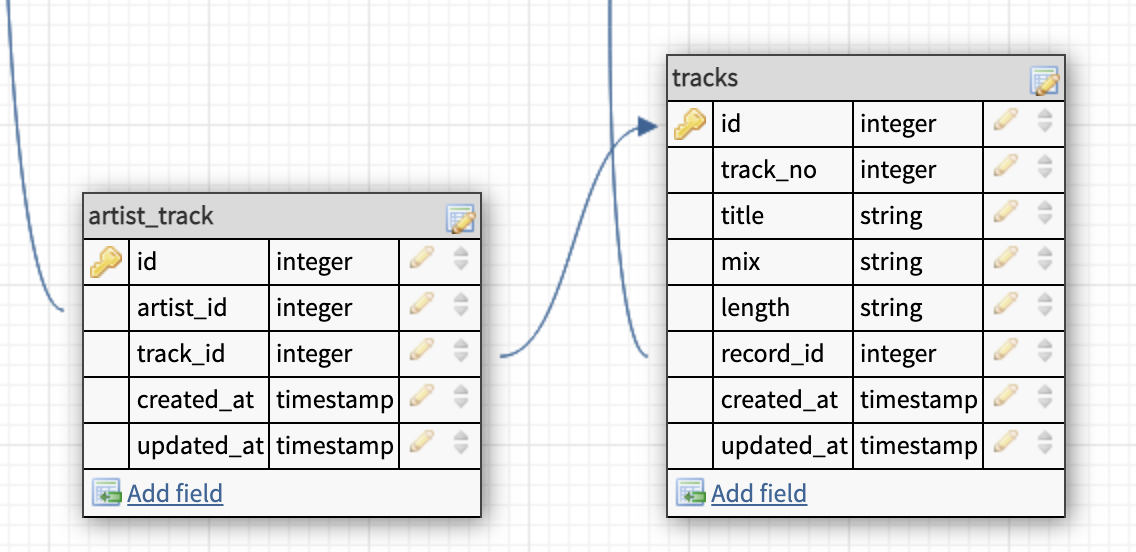
What we end up with
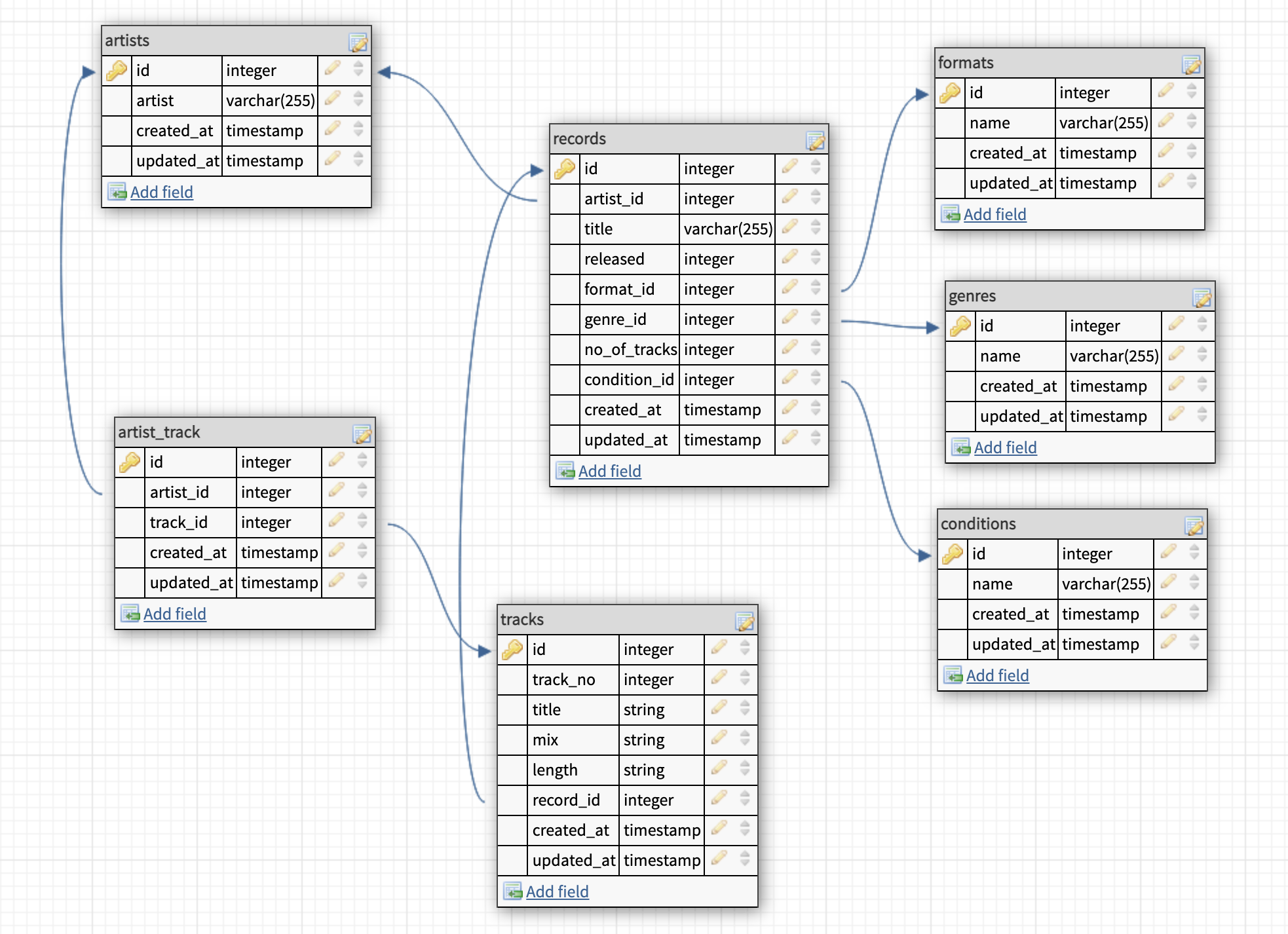
After our extraction exercise we end up with a database model that looks like this.
Nullable columns
When it comes to nullable columns, SQL and Laravel Migrations differs a little. All the tables we have created with SQL has allowed a null value in all the columns except the id one but that is generated automatically. The ones we have created with a Laravel migration does not allow for the value to be null unless we explicitly tell it to.
To make a column not to allow a null value with SQL you add the keywords NOT NULL to the column definition.
1title varchar(255) NOT NULL,This is a good practice to add to all columns that should never be allowed to contain a null value.
Laravel does this by default in its migrations and if you want the value to be nullable you need to define that in your migration.
1$table->string('comment')->nullable();One important thing is that a foreign key column never should be nullable, since I think it defeats the purpose of having it in the first place.
So to make our table force us to enter values for all the required fields we need to update our creation scripts.
They will look like this after that update.
1CREATE TABLE artists( 2 id int auto_increment primary key, 3 artist varchar(255) NOT NULL, 4 created_at timestamp, 5 updated_at timestamp 6); 7 8CREATE TABLE records( 9 id int auto_increment primary key,10 artist_id int NOT NULL ,11 title varchar(255) NOT NULL,12 released int NOT NULL ,13 format_id int NOT NULL ,14 genre_id int NOT NULL ,15 no_of_tracks int NOT NULL ,16 condition_id int NOT NULL ,17 FOREIGN KEY (artist_id)18 REFERENCES artists (id)19 ON DELETE CASCADE,20 FOREIGN KEY (format_id)21 REFERENCES formats (id),22 FOREIGN KEY (genre_id)23 REFERENCES genres (id),24 FOREIGN KEY (condition_id)25 REFERENCES conditions (id)26);27 28-- The formats, genres and conditions tables29CREATE TABLE <table name> (30 id int auto_increment primary key,31 name varchar(255) NOT NULL,32 created_at timestamp,33 updated_at timestamp34 );35 36CREATE TABLE tracks(37 id int auto_increment primary key,38 track_no int NOT NULL ,39 title varchar(255) NOT NULL,40 mix varchar(255),41 length varchar(255) NOT NULL ,42 record_id int NOT NULL,43 created_at timestamp,44 updated_at timestamp,45 FOREIGN KEY (record_id) REFERENCES records(id)46 ON DELETE CASCADE47);Default values on columns
You can define default values on a column in case the record you are trying to insert doesn't provide one.
This is very useful if you have a column that almost always have the same value. Take out mix column in our
tracks table as an example, in 95% of the cases it would be album mix or something similar.
What we did in the Nullable section and set the mix column to nullable we can remove that and use a default
for the column instead if we like.
It would look something like this.
1CREATE TABLE tracks( 2 id int auto_increment primary key, 3 track_no int NOT NULL , 4 title varchar(255) NOT NULL, 5 mix varchar(255)NOT NULL DEFAULT('Album mix'), 6 length varchar(255) NOT NULL , 7 track_artist varchar(255) NOT NULL, 8 record_id int NOT NULL, 9 created_at timestamp,10 updated_at timestamp,11 FOREIGN KEY (record_id) REFERENCES records(id)12 ON DELETE CASCADE13);Laravel Migration
1Schema::create('tracks', function (Blueprint $table) { 2 $table->id(); 3 $table->int('track_no'); 4 $table->string('title'); 5 $table->string('mix')->default('Album mix'); 6 $table->string('length'); 7 $table->string('track_artist'); 8 $table->foreignId('record_id') 9 ->constrained('records')10 ->onDelete('cascade');11 $table->timestamps();12}Conclusion
I use this approach when I need to create a database model. However, I use TDD to drive my development and in this case I would have started with just two tables.
- Records
- Tracks
Then during my process I would extract the one-to-many and many-to-many relationships. I might even extract one-to-one relationships if need be. If you have a users table, and you store a lot of profile information in that table, information that you seldom display other than on the profile page then consider moving it to a user_profiles table.
Another good way to check if something needs to be extracted is the visual test of your tables.
If some column has the same value over and over you should consider extracting it. When I say value here I didn't mean the foreign key ids.
1+----+----------------+----------------------+------+-------------------|2| id | author_name | title | part | series |3+----+----------------+----------------------+------+-------------------|4| 1 | Jordan, Robert | The Eye Of The World | 1 | The Wheel Of Time |5| 2 | Jordan, Robert | The Great Hunt | 2 | The Wheel Of Time |6+----+----------------+----------------------+------+-------------------|Consider this table.
- The author name is repeated, so it could be extracted.
- The series is repeating so it could be extracted.
The other columns can stay as is.
One thing you need to consider as well is that extraction of the columns can go to far and force you to make joins between too many tables and thus making your database model hard to understand.
So try to follow these rules
- Don't repeat yourself (too much)
- Keep it simple stupid (don't overcomplicate things)
- Extract when it makes sense (don't extract to absurdity)
Or in programmer acronyms
- DRY (Don't Repeat Yourself)
- KISS (Keep It Simple Stupid)
- EP (Extraction Principle (Probably made this one up, but it's still a valid point))
I hope this has given you some guidance on how to approach the building of a good database model. It does in no way cover everything and every case since that would require several hundreds of pages.
What about performance and indexes? Well, it's a big subject, and I think this post is long enough as is. That just might come as a second part to this post.
When to use json columns?
There are actually a few times that json columns are perfect and can be used for what I consider them made for. Let's say that you do have an external API that you fetch thousands of records or that you allow the user to upload json encoded data, for example in sales data or inventory data. To make those request fast and as CPU friendly as possible you can store the json payload into a table with a json column temporarily and then schedule a job that processes the payload and inserts them into other tables and columns.
//Tray2